Shutter Interaction Dataset
About the Dataset
The Shutter Interaction Dataset is a new dataset for predicting human intent with a public robot. This dataset provides a rich observation space that includes human and robot pose as well as some engineered features about relative pose. This dataset was used in the paper "Predicting Human Intent to Interact with a Public Robot: The People Approaching Robots Database (PAR-D)" - code for the paper can be found here. "
Collection
A Shutter robot was mounted to a movable cart and placed in two university lobbies to collect data. Data was collected from Shutter's sensors, including two forward-facing Microsoft Azure Kinect sensors that collect body tracking data. Additional data comes from various ways in which Shutter interacts with users, such as Shutter's motion, gaze, text-to-speech, and three buttons on the front side of the cart. Data collection took place across 13 days in August 2022.
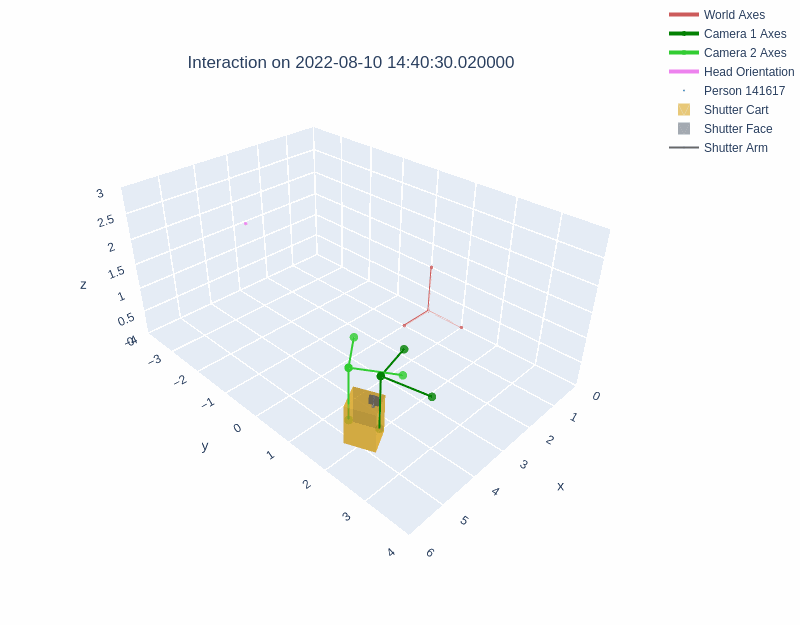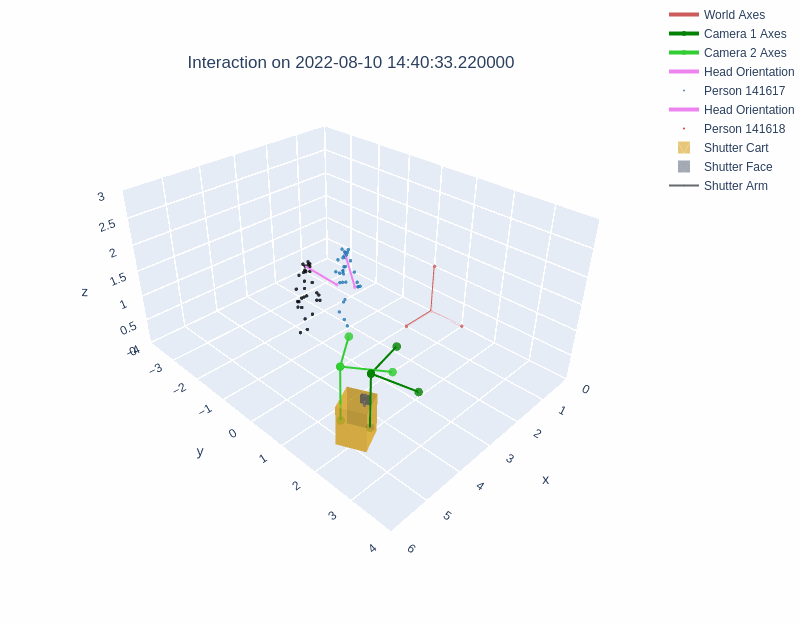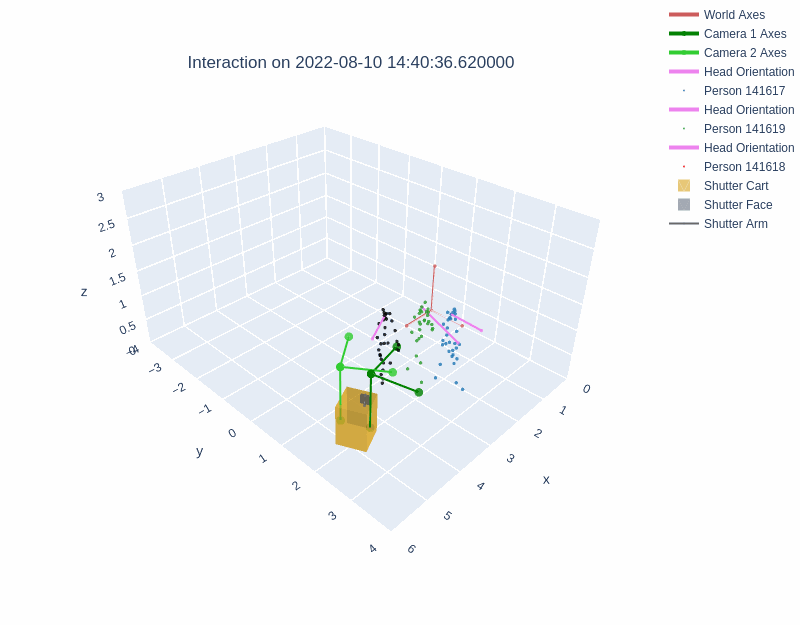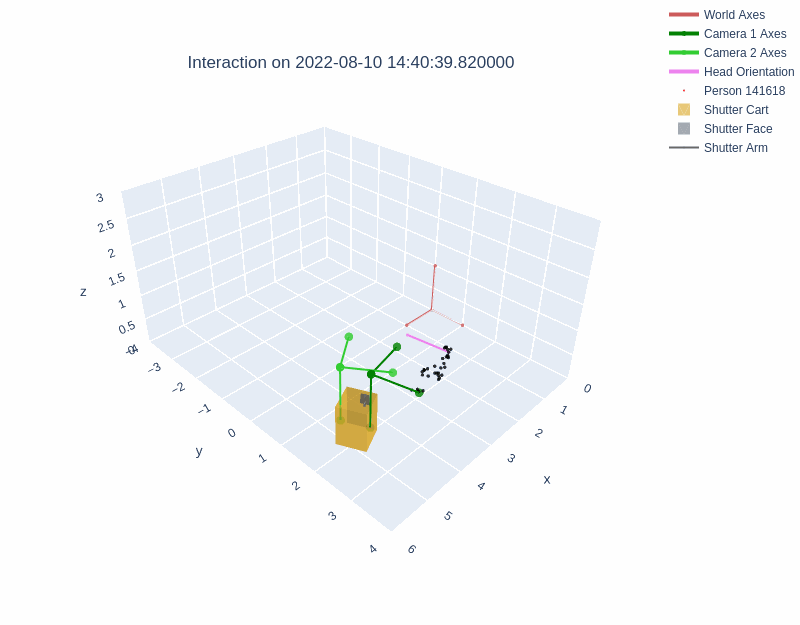
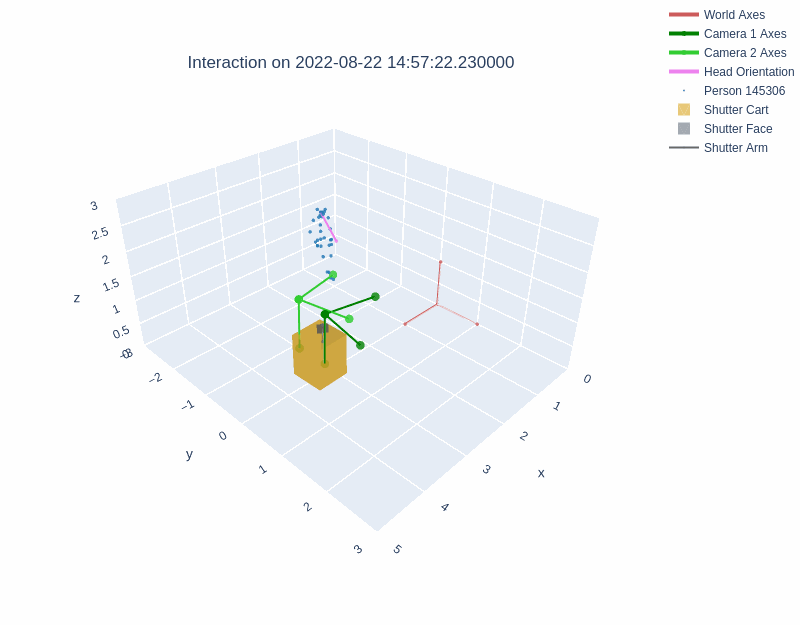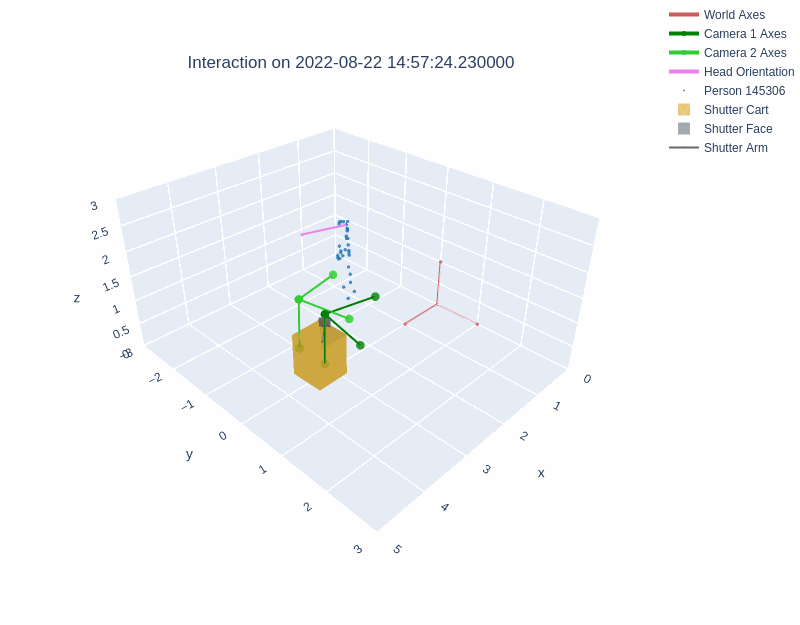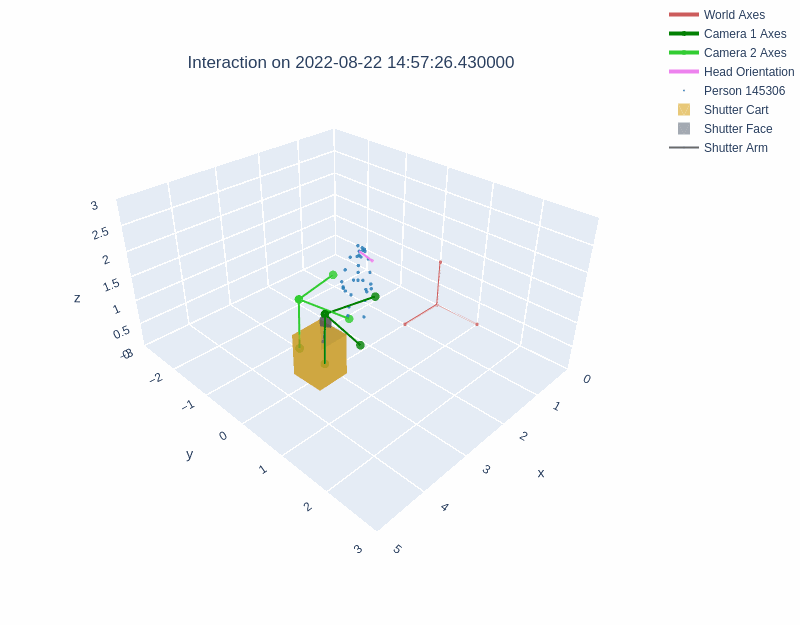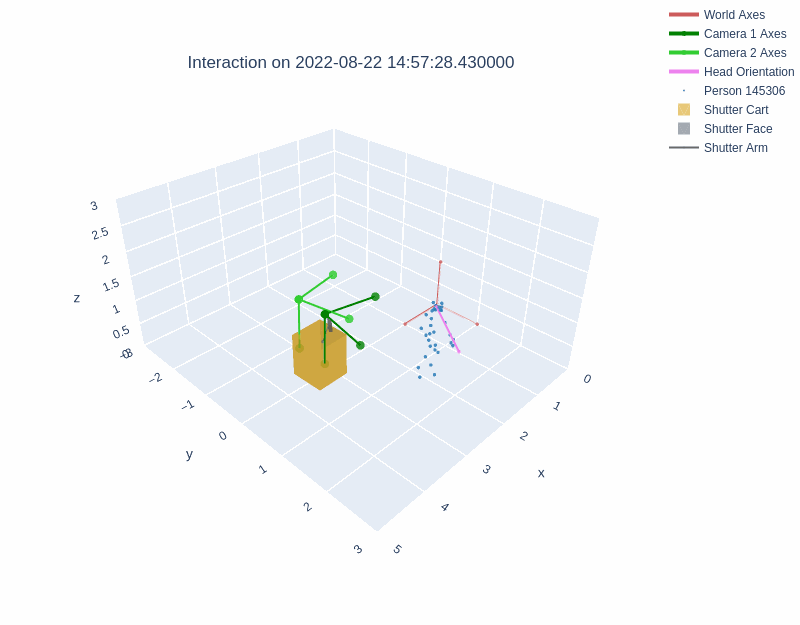
The diagrams below illustrate the different layouts of the lobbies. The visualizations above depict interactions recorded in Lobby 1 and Lobby 2 respectively.
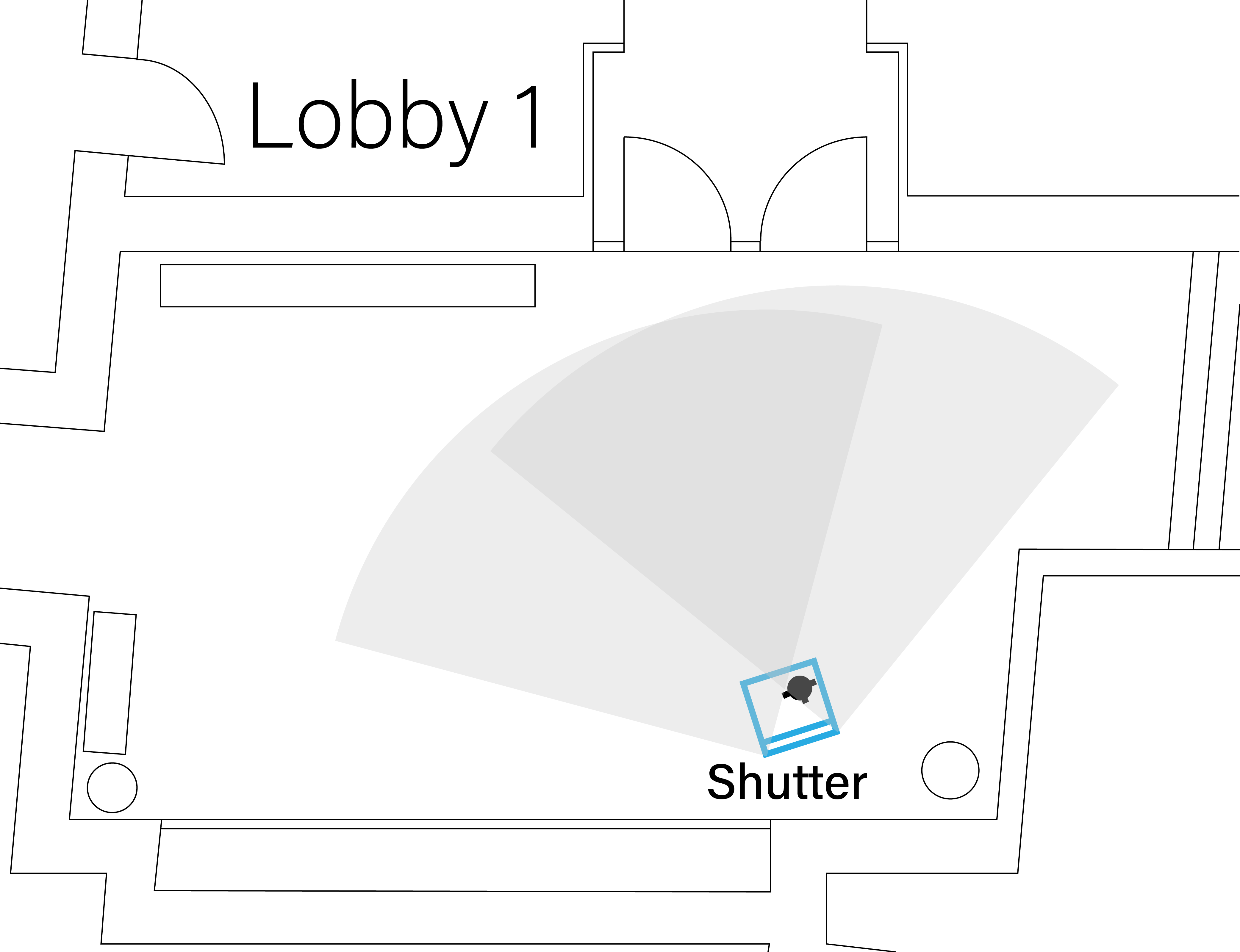

Interaction Walkthrough
During an interaction, the behavior of the robot was managed with a behavior tree. Shutter maintained a resting state until a person entered the field of view of either Kinect sensor. Shutter then randomly selected one of three greeting behaviors. The interaction continued beyond the greeting phase if the person pressed any of the cart's three buttons. Once an interaction had started, Shutter tracked the person with both body motion and gaze, explained its role as a photographer, took a photograph with a camera attached to its head, and showed the photograph on a monitor behind the robot. Then, Shutter verbally praised the image and displayed a QR code for the user to access the image. Interactions could be halted by users at any time by exiting the robot's field of view, after which the robot returned to a resting state.

The Kinect sensors used to collect body tracking data and three buttons for a user to interact with Shutter.
Dataset Components
Here is a high-level overview of the Lobby 1 and Lobby 2 datasets:
| Lobby 1 | Lobby 2 | |
|---|---|---|
| Dataset size | 131 MB | 151 MB |
| Number of positive scenarios (interactions) | 125 scenarios | 189 scenarios |
| Number of negative scenarios (non-interactions) | 221 scenarios | 522 scenarios |
| Average scenario length | 15.8 seconds | 8.81 seconds |
| Average number of people in each frame | 1.45 people | 1.14 people |
| Average number of people per scenario | 2.07 people | 2.32 people |
| Maximum number of people visible in one frame | 4 people | 5 people |
Skeleton Data
All of the skeleton and Shutter robot position information are in a fixed coordinate frame which is positioned at a static point in the environment.
For each of the joints listed below, the dataset includes x, y, z coordinates of that joint as well as sin and cos measurements for each dimension. This data comes from the Kinect cameras and was transformed to the environment coordinate frame.
- ankle left
- ankle right
- clavicle left
- clavicle right
- ear left
- ear right
- elbow left
- elbow right
- eye left
- eye right
- foot left
- foot right
- hand left
- hand right
- handtip left
- handtip right
- head
- hip left
- hip right
- knee left
- knee right
- neck
- nose
- pelvis
- shoulder left
- shoulder right
- spine chest
- spine navel
- thumb left
- thumb right
- wrist left
- wrist right
Robot Position
The dataset includes the x, y, and z positions of three places on the Shutter robot: cart, robot base, and robot head (see image below). The sin and cos measurements in each dimension for the three points are also recorded.

The three points on the Shutter robot recorded in the Shutter Interaction Dataset and the coordinate axes for each point.
Robot to Person Measurements
The dataset contains measurements from a user's head and pelvis to the robot head and cart. These measurements include both distance between the person joint and robot point and the cos and sin measurements for each combination.
Shutter Data
The dataset also includes information about Shutter's actions and a user's interaction with Shutter. This includes Shutter's current action, if each button on Shutter's cart is currently being pressed, Shutter's greeting, what fsm state Shutter is in (waiting, greeting, or interacting), and Shutter's current speech, if any.
Other Features
The dataset contains the following other features:
- pid - person id
- original frame id - original Kinect camera to record this data, either master or sub
- original file name - original file to store the data
- resampled timestamp - new timestamp taken from the three data sources
- skel timestamp - original timestamp from the skeleton sata source
- tf timestamp - original timestamp from the tf data source, which records robot position and robot to person measurements
- shutter timestamp - original timestamp from the shutter data source
- deployment location - location in which data was recorded, either location A or location B